#3 Before the agent acts, something decides what it acts on
On queues, priority, and the design decision I almost got wrong.

Before any message reaches the agent, it has to wait in line.
Not because the system is slow. Because two things can arrive at once — I send a message, and a scheduler job fires — and processing them concurrently is how you get race conditions: two coroutines touching the same state, writing to the same conversation, sending two replies at once. The queue serialises work. One thing at a time, in the right order.
The first design question is what “right order” actually means.
What I considered
The obvious starting point is a single priority queue with three levels:
HIGH for my direct messages
MEDIUM for scheduler triggers
LOW for background work.
Python’s standard library already gives me asyncio.PriorityQueue: no dependencies, async-friendly, and superficially a perfect fit.
The problem shows up when I think about how the system actually behaves. It operates in two modes at once.
Reactive: I send a message, the agent responds, I am mid-conversation.
Autonomous: the agent wakes up at 3am, replies to a customer, syncs my calendar — no active conversation, no human in the loop.
In reactive mode, I want strict serialisation. Nothing should interrupt a flow I am actively in. In autonomous mode, I want the opposite: background jobs should run freely. The Gmail poller and the Garmin sync should not block each other just because they happen to land at the same time.
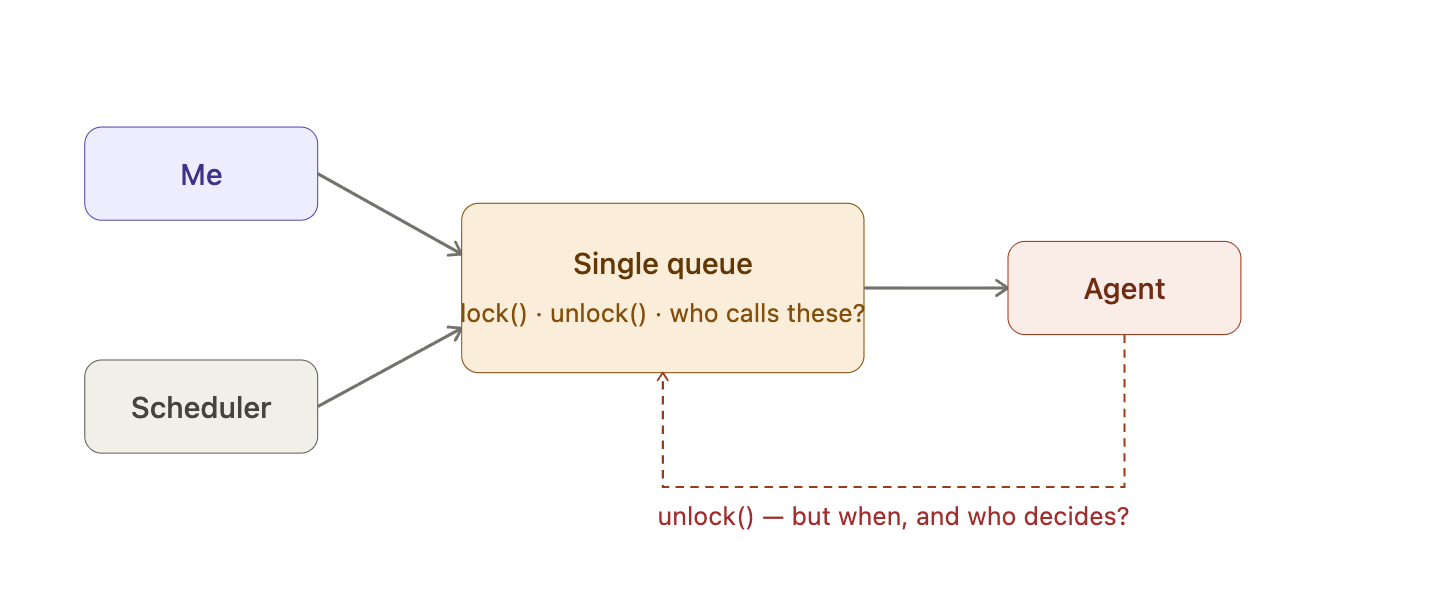
A single queue plus a lock tries to cover both cases. In practice, that means introducing a flag that says: stop processing anything new until I say otherwise. A lock, in this context, is exactly that — a flag that tells the queue to hold everything until explicitly released.
Simple in theory. Messy in reality.
Something has to set that flag and clear it again. Which means something has to know exactly when a conversation starts and when it is safe to say it has ended. I quickly end up with lock() and unlock() on the interface, session state leaking across layers, and a question with no clean answer: who is actually responsible for calling them? The gateway? The agent? That kind of shared coordination logic is exactly how you get bugs at 3am.
What I am building instead
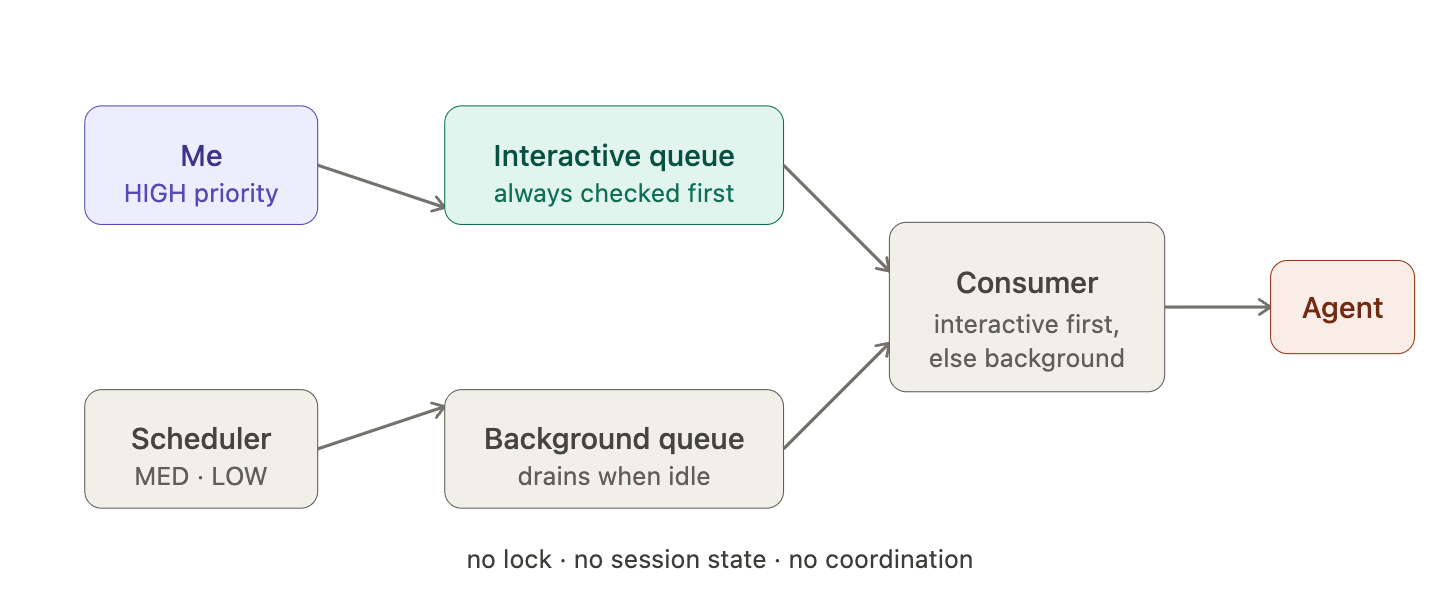
Two queues, one consumer.
My direct messages go into an interactive queue. Everything the system generates autonomously — scheduler triggers, background work — goes into a background queue. The consumer always checks the interactive queue first, and only drains the background queue when the interactive one is empty.
No lock. No session state. No coordination between layers. When I’m mid-conversation, my replies keep landing in the interactive queue — the background queue waits naturally, because the consumer always looks there first. When I’m not around, background drains freely.
Priority becomes the implicit policy rather than an explicit lock. The behaviour I wanted — my input always takes precedence — falls out of the structure rather than being enforced by state.
What this design doesn’t solve yet
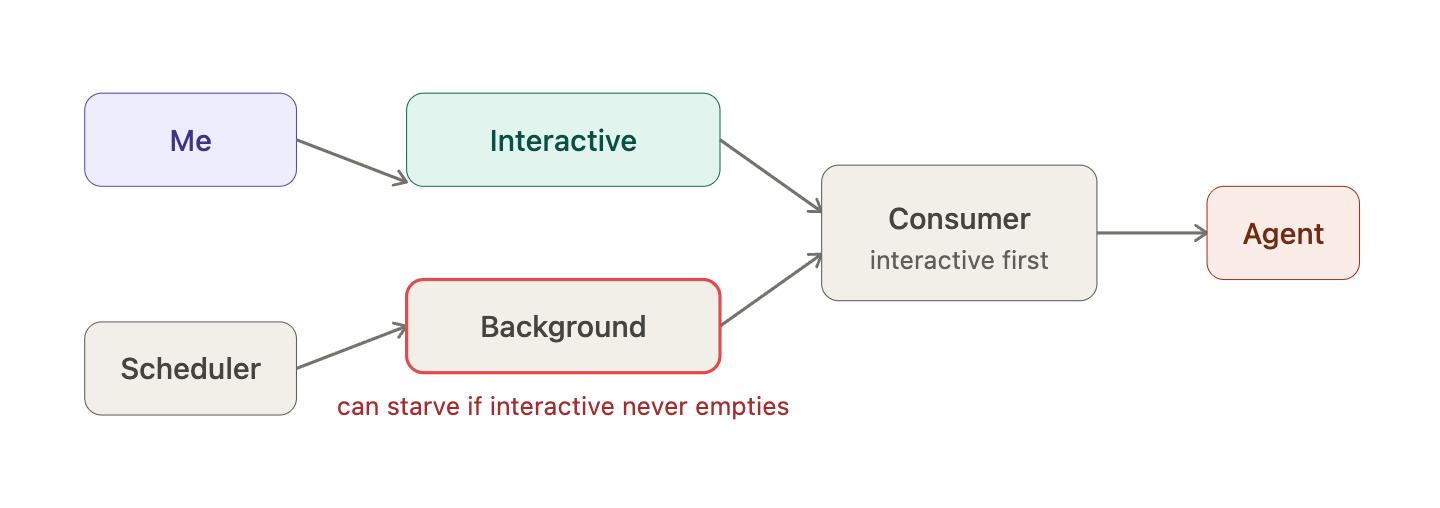
This is the right first decomposition. It is probably not the final one.
The most obvious tradeoff: if interactive traffic never stops, background work can wait forever. For most background jobs — a Gmail poll, a Garmin sync — that is fine. But some jobs eventually acquire real stakes. A retry that unblocks something important, or a scheduled task with a real deadline, should not be indefinitely postponed just because I happen to be active.
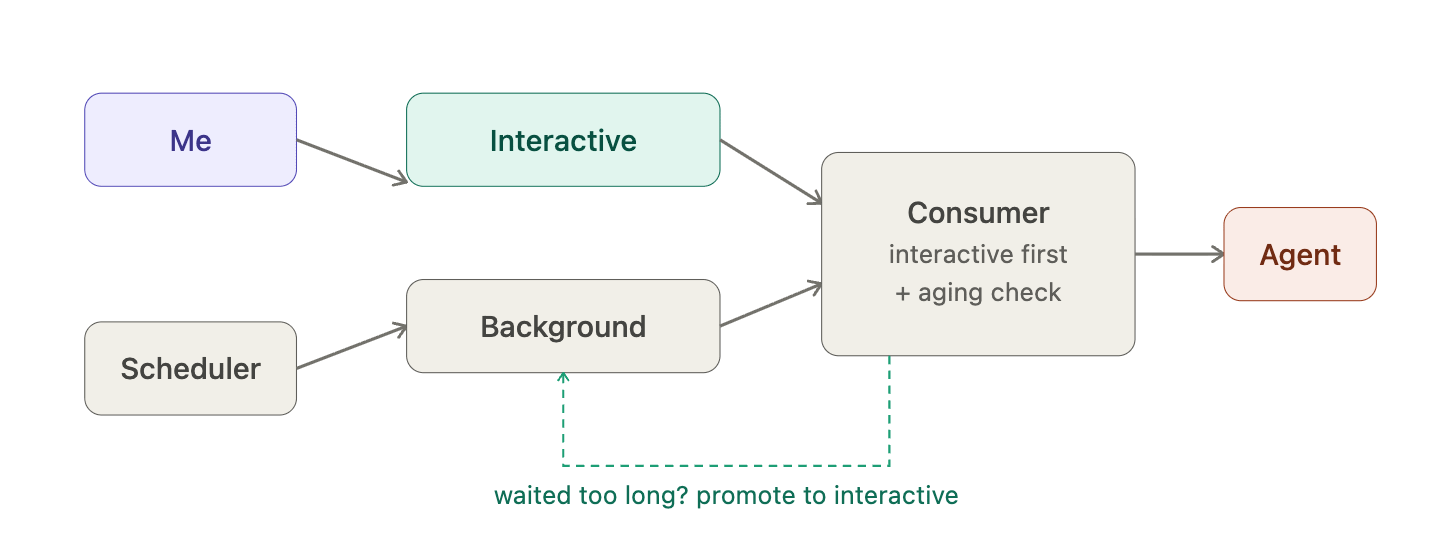
When that becomes a real problem, the consumer needs to get smarter. The most natural fix is aging: items that have been waiting beyond some threshold get promoted, regardless of which queue they came from. The policy stays structural — no explicit session state — but background work gets a guaranteed worst-case wait.
There is a related limitation that only shows up when I am not there at all. Once the interactive queue is empty, background work drains in arrival order. That is fine at small scale. It stops making sense once there are enough jobs for their differences to matter, because arrival order is a terrible proxy for importance. A retry that unblocks a pending customer reply should not wait behind a routine Garmin sync just because it arrived a second later. At some point, “background” stops being one class of work. Items will need more metadata — urgency, deadlines, maybe job type — so the consumer can make better decisions even when no human is in the loop.
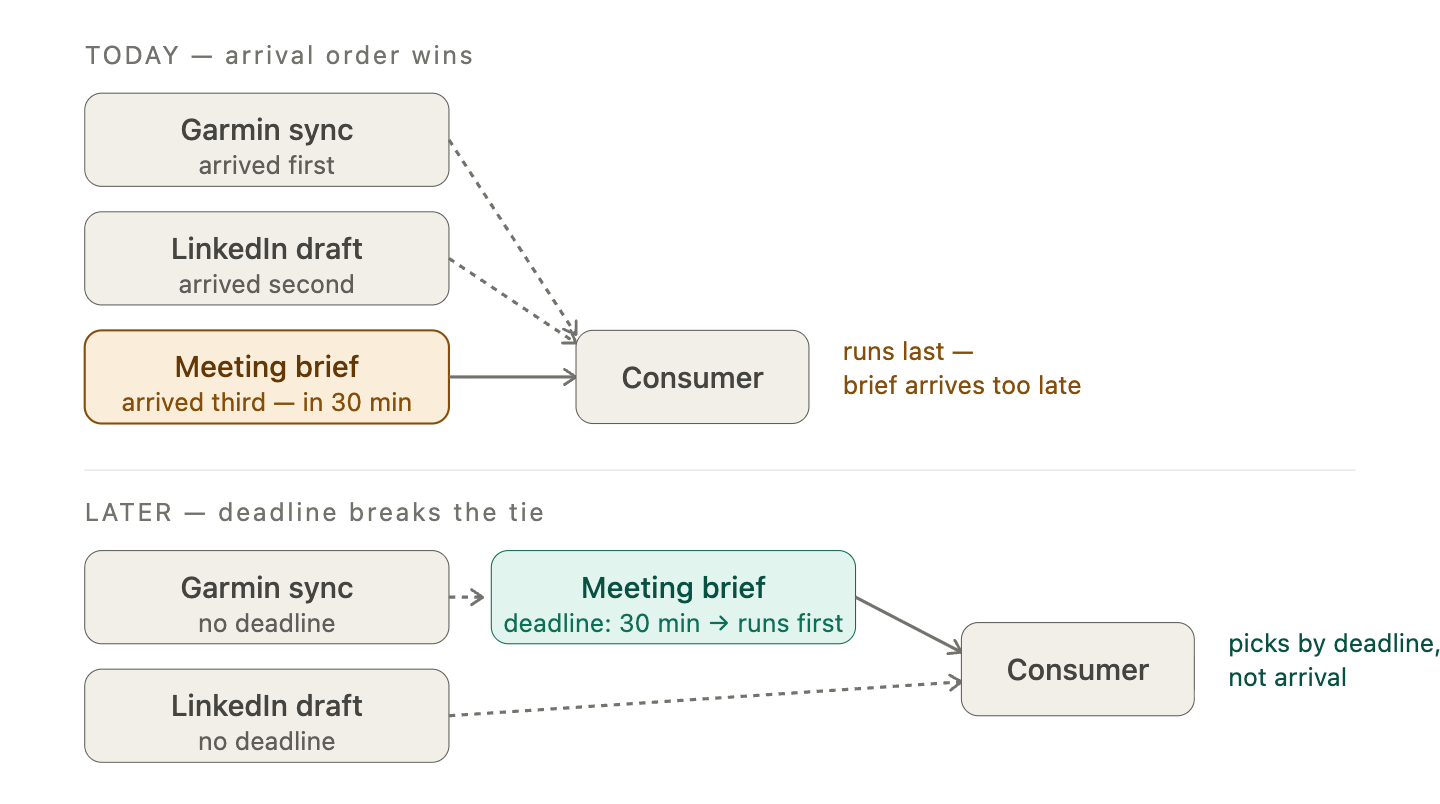
The second issue is that “background” is currently a single bag holding things that are not really the same kind of work. Scheduler triggers, polling loops, retries, and internal follow-ups all land in the same queue. That works now, because I don’t have enough background jobs for the distinction to matter. But as the system grows, that bag will want to split into dedicated lanes: scheduled user-visible tasks, maintenance and polling, internal continuation jobs — each with its own priority behaviour and starvation rules.
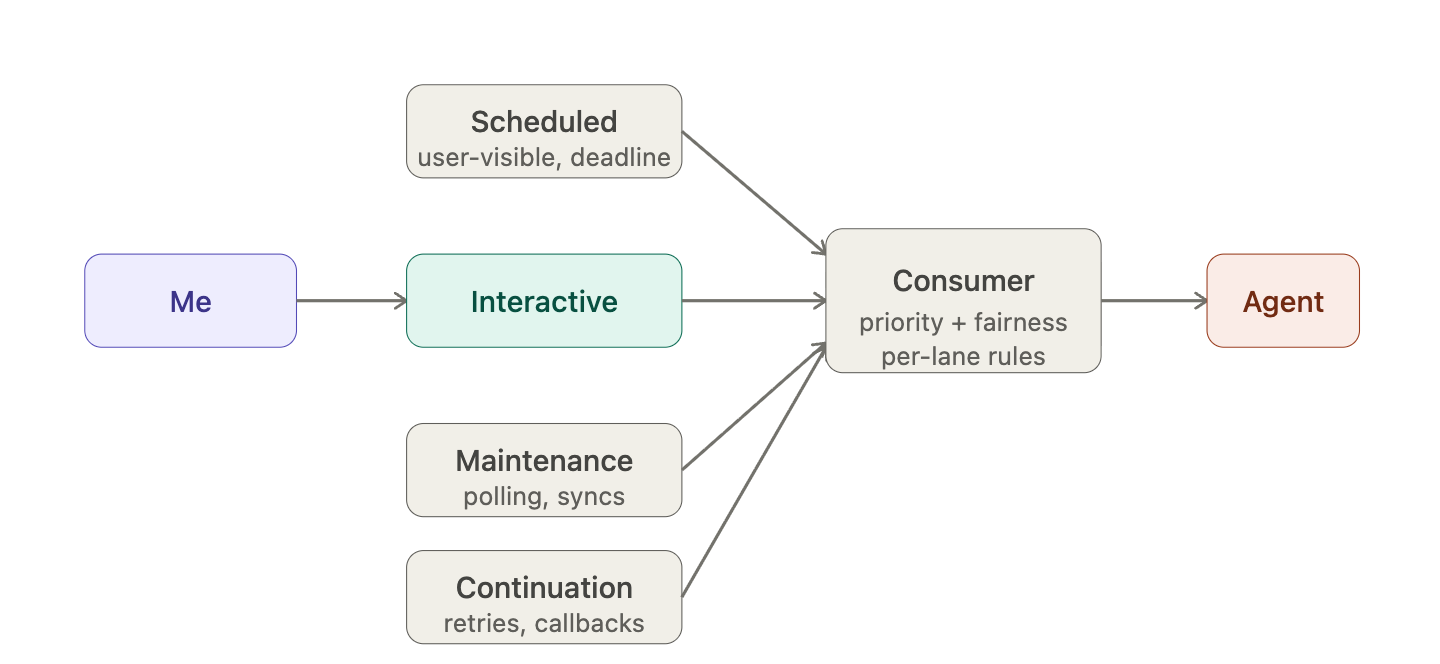
None of this changes the design I'm building today. It changes the implementation inside the consumer, which is exactly where it should change. The interface — two methods, put and get — stays the same throughout. That is the point of designing the swap point correctly from the start.
The interface
The two-queue decision lives inside the implementation. Nothing outside it knows or cares.
class Priority(Enum):
HIGH = 1 # my direct messages
MEDIUM = 2 # scheduler triggers
LOW = 3 # background work
class QueueProtocol(Protocol):
async def put(self, message: InboundMessage, priority: Priority) -> None: ...
async def get(self) -> InboundMessage: ...Two methods. Every caller — the Telegram adapter, the scheduler, the agent — depends on exactly this contract and nothing more. The actual implementation today is an in-memory queue: two asyncio.PriorityQueues living in the process, fast, zero dependencies, gone if the process restarts. That’s fine for now. Tomorrow it could be something backed by Redis — a separate server that persists the queue to disk, survives restarts, and can be shared across multiple processes. The interface doesn’t change either way. That’s the swap point.
What I ruled out
Session gating with explicit lock/unlock. My first instinct was to put lock(), unlock(), and a session_active flag directly on the queue interface. The problem: the moment those methods exist, every piece of code that uses the queue — the Telegram adapter, the scheduler, the agent — has to answer the same question: do I need to call lock() before I act? Do I need to call unlock() when I'm done? The only piece that could plausibly know the answer is the agent, which means the agent ends up managing the queue's internal state — something that has nothing to do with its actual job. And if the agent crashes mid-conversation without calling unlock(), the queue stays locked forever. The two-queue design sidesteps all of this. No caller ever has to think about lock state. The policy is in the structure, not in the discipline of every caller remembering to do the right thing.
Redis from day one. Redis would buy me persistence across restarts: if the process dies with messages in flight, they survive. The honest answer is that I do not need that yet. At this stage, losing an in-memory queue on restart is acceptable. The interface is the insurance policy. When persistence becomes necessary, I can write RedisQueue, swap a line in setup, and leave the rest of the system untouched.
A single asyncio.PriorityQueue with numeric priorities. This solves ordering, but not separation. With one queue, items from different sources still compete inside the same structure. A scheduler trigger and a background task with the same priority end up interleaved by insertion order, even though conceptually they belong to different modes of operation. Two queues make that distinction explicit. Interactive work has a dedicated fast lane. Background work only runs when that lane is empty. The policy is visible in the architecture and much harder to violate by accident.
Why this matters for what I’m building
The whole point of this system is that it runs autonomously most of the time. Customer emails replied to at 3am. Inventory alerts drafted. Referral sequences triggered. I am not there.
But when I am there — when I send a message, tap approve, or review a digest — I need the system to be fully focused on me. No background task cutting into the middle of a confirmation flow. No scheduler job stealing the next turn.
The queue is what guarantees that. Not by checking whether “a session is active,” but by encoding the rule directly into the architecture: my lane and the system’s lane, with a clear priority between them.
It is a small design decision. It is also one of the things that makes the rest trustworthy.
What’s next
Storage. Everything the system needs to remember across restarts: pending confirmations waiting for my tap, the append-only event log that lets me replay what happened at 3am, and the handful of key-value pairs the scheduler needs to not replay the entire Gmail inbox after a process restart.
Same approach — design the interface first, pick the simplest implementation that earns its complexity, build to swap.
- Louis