#2 Building a personal AI agent I actually trust
Envelopes, middleware, and why infrastructure comes before intelligence

Last weekend I built a quick prototype to see how far I could get in two days. Telegram bot, Gmail integration, a basic planner. Rough around the edges, no tests, but enough to feel the idea working. Enough to know I wanted to build the real thing.
So that’s what this is. Not a rewrite — a start. With the weekend experiment as a reference for what the system should do, and a clean slate for how it should be built.
The specific moment I knew the prototype wasn’t the foundation: I thought about adding WhatsApp as a second interface. I opened the code and found Telegram in a dozen places that had nothing to do with Telegram — business logic, email notifications, confirmation flows. It had seeped into everything after 48 hours. That’s the kind of thing that doesn’t hurt on day one. It hurts on month six.
First things first
Setting the right development environment will enable whatever I build next outlast my 48h POC.
TDD from the start: The prototype has no test suite — that was fine for a weekend experiment. It’s not fine for something I want to depend on and build on over years. Tests come before features.
No LLM, just yet: I am starting with the foundations, the envelope, the middlelayer and MCP. No LLM, no email, no Telegram. Just the layer everything else will sit on.
The unglamorous part
Taken together, the pieces I will explore in this section — the envelope, the pipeline, the middleware — form what’s usually called a gateway layer. It’s the normalized entry point that sits between the outside world (Telegram, email, scheduled jobs) and the agent. Every message gets sanitized, traced, and policy-checked before anything intelligent touches it. OpenClaw, the closest open-source equivalent to what I’m building, has an explicit gateway as a standalone Node.js daemon. Mine is a set of composable Python modules with clean boundaries. Same responsibility, different philosophy.
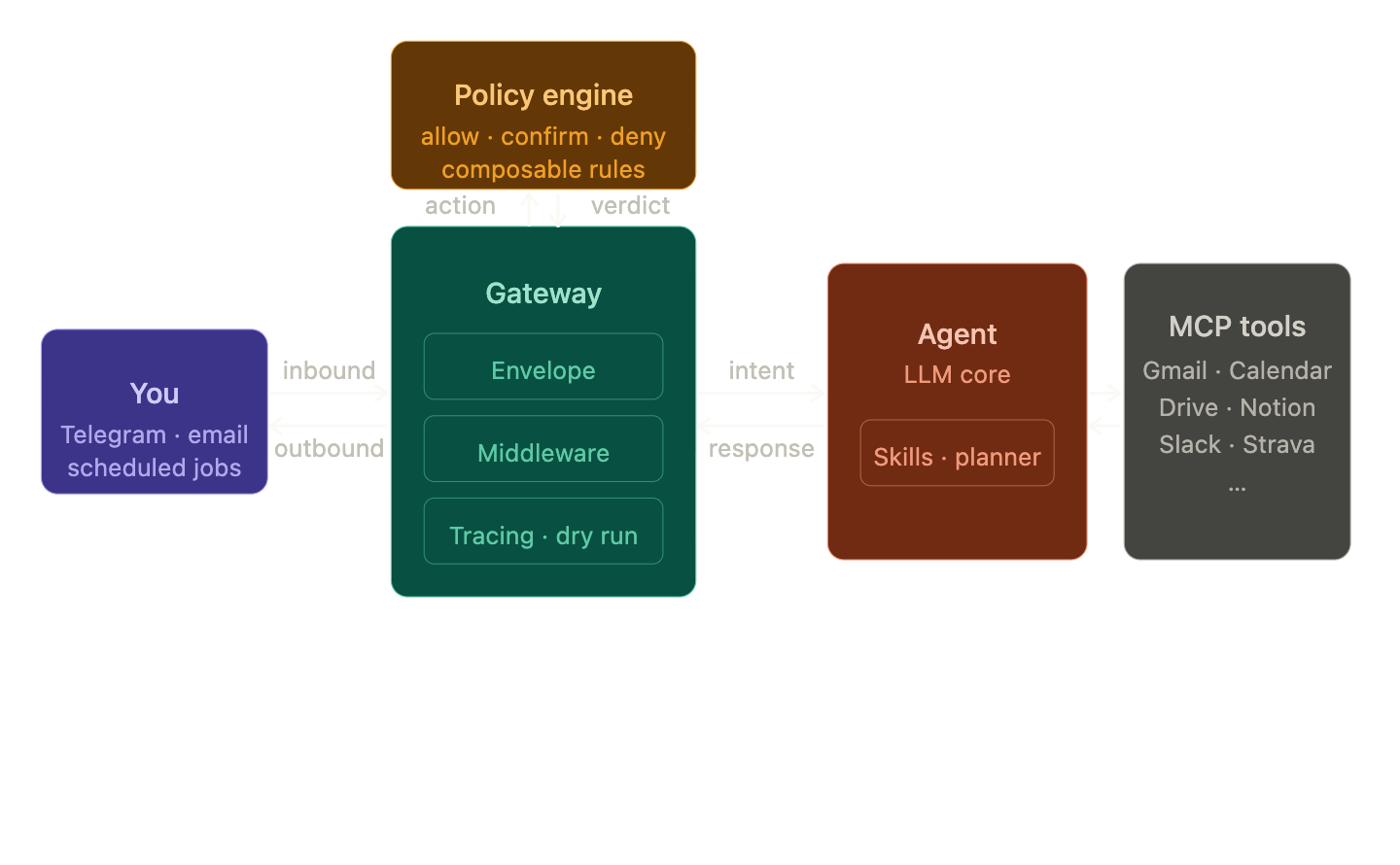
1. The envelope pattern — how I talk to the agent
In the prototype, Telegram leaked everywhere — not just the bot handler, but email notifications, confirmation flows, planner responses. Every layer knew too much.
The fix is a normalization step at the boundary. Whatever enters the system — a Telegram message, an incoming email, a scheduled job — gets converted into the same structure before any business logic sees it. I’m calling it InboundMessage: a channel, a user ID, text or voice bytes, and a trace ID. The agent, the skills, the planner — none of them care where it came from.
Same logic on the way out. The agent produces an OutboundMessage. The interface adapter’s only job is to translate that into whatever the messaging app expects.
Worth clarifying: this is Me ↔ Agent communication only. The envelope has nothing to do with how the agent talks to tools — that’s MCP’s job (see below). It’s purely the channel between me and the system, and that channel should be swappable without touching anything else.
For now, Telegram is the only interface and I’m happy to keep it that way. Inline action buttons — approve, revise, discard, later — are genuinely the right UI for an agent acting in your name. Tapping “approve” on a drafted email isn’t an afterthought; it’s the interaction model. The envelope pattern just means adding WhatsApp or a CLI is a one-day job instead of surgery.
2. MCP — how the agent talks to tools
In the prototype, I wrote my own Google API wrappers. They worked, but they’re maintenance surface I don’t want to own — retry logic, auth edge cases, schema drift when Google updates something upstream. In this version, I’m betting on MCP servers instead. My job is to write skills and configure which MCP servers each skill needs. Not to maintain API wrappers.
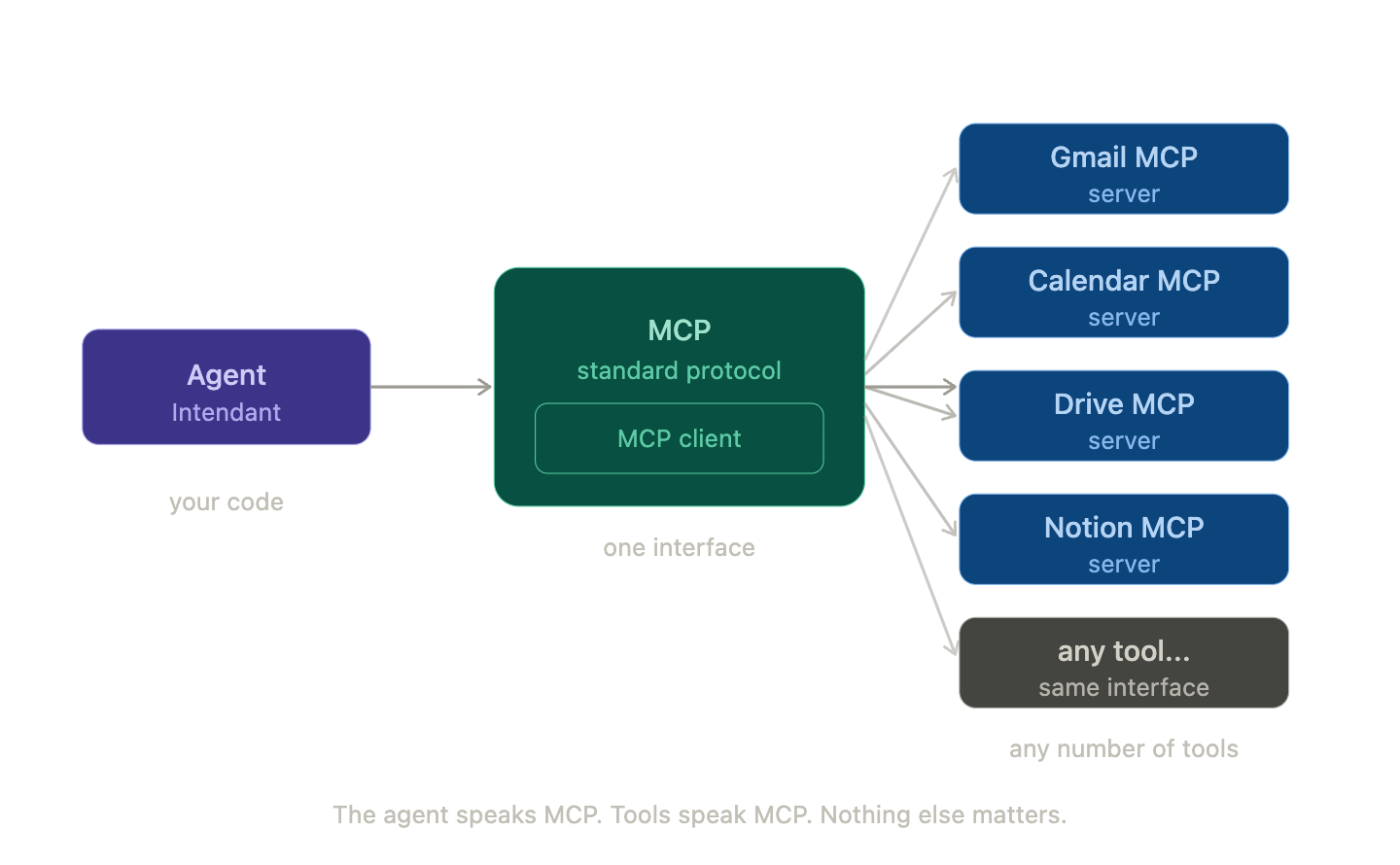
The trade-off is real: third-party MCP servers vary a lot in quality, and a server you don’t maintain is a dependency you can’t fix when it breaks at 2am. I’m accepting that in exchange for not owning a different kind of rot. For most of what this system needs, that’s the right call. For anything where reliability is critical and no good MCP server exists, I’ll write the wrapper. Strava is already on that list.
Anthropic dropped MCP as an open standard and the ecosystem moved fast — servers for Gmail, Calendar, Drive, Notion, Slack, Linear appeared quickly. As that ecosystem matures, this system absorbs those improvements passively. That’s worth something.
3. The middleware pipeline — boring infrastructure that matters a lot
Before any message reaches the agent, it passes through a chain of middlewares. If you’ve never worked with middleware: think of it as a series of wrappers, each one getting a chance to do something before and after the next one runs. Like Russian dolls, except useful.
The chain has three layers.
Tracing wraps everything. Every request gets a unique trace_id generated at the boundary and bound to the log context for its entire lifetime. When something goes wrong — and it will — you have a single ID that ties together every log line, every tool call, every error that happened during that request. Without this, debugging a system that acts autonomously while you sleep is guesswork.
Logging sits inside tracing. It records what came in, and how long it took to come out. That’s it. It doesn’t know what happened in between — that’s not its job. The separation is deliberate: a logger that knows too much becomes a liability when you refactor.
Dry run sits inside logging, right before the handler. When the flag is set, execution stops here. The system tells you what it would have done instead of doing it. For a system that sends emails and manages calendars in your name, a kill switch is not a nice-to-have.
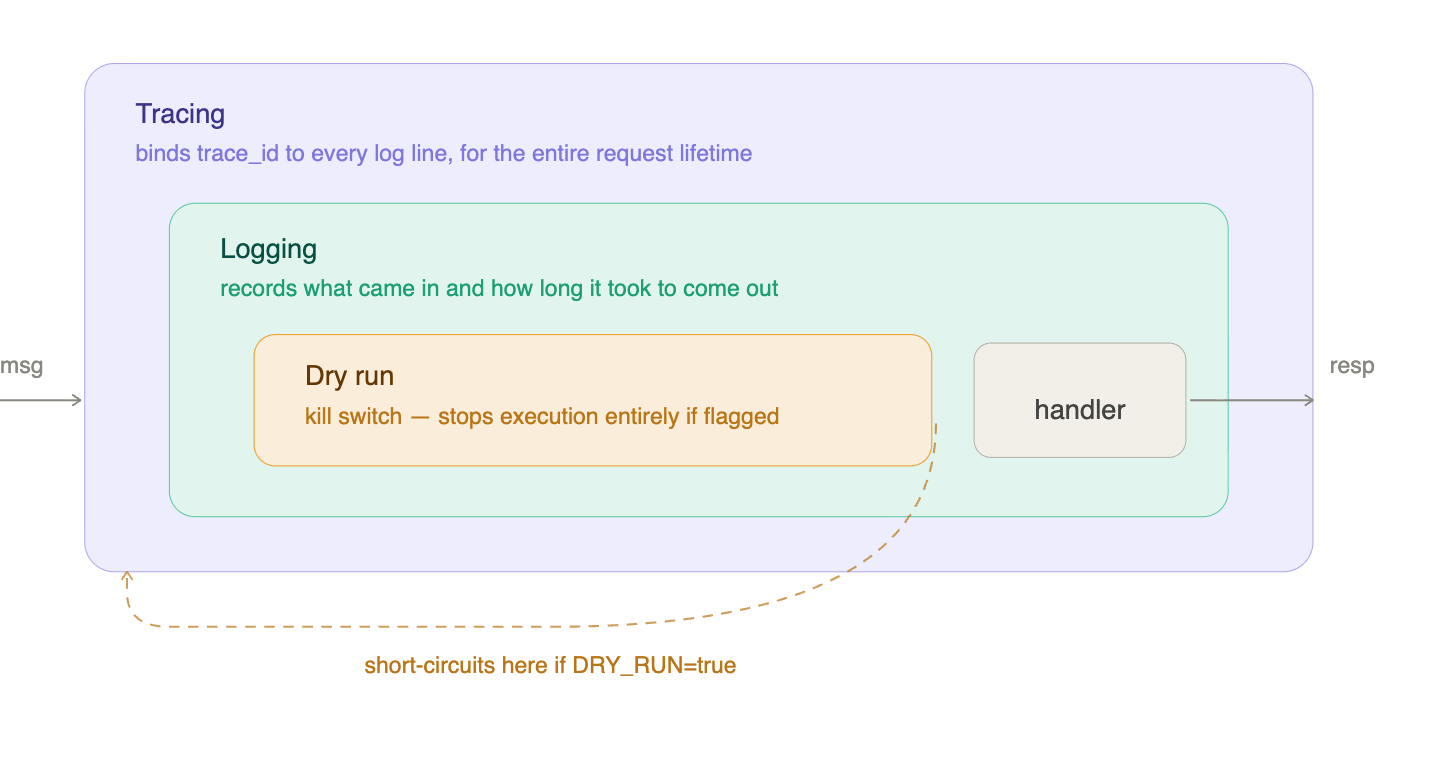
Each middleware is independent. Adding one doesn’t touch the others. Removing one doesn’t break anything. The order matters — tracing has to wrap everything — but the rest is composable. This is the kind of thing that feels like over-engineering on day one and saves you on day ninety.
The principle behind all of this: infrastructure before intelligence. The smarter the system gets, the more expensive bugs become. You don’t build the roof before the walls.
4. The policy engine — what the system is allowed to do
The policy engine answers one question: should this action execute?
Every action the system wants to take — send an email, create a calendar event, reply to someone — gets evaluated before it happens. The engine runs it through every registered policy and returns the strictest verdict. Three possible outcomes: allow, confirm, or deny. If ten policies say allow and one says deny, the answer is deny. The strictest verdict always wins.
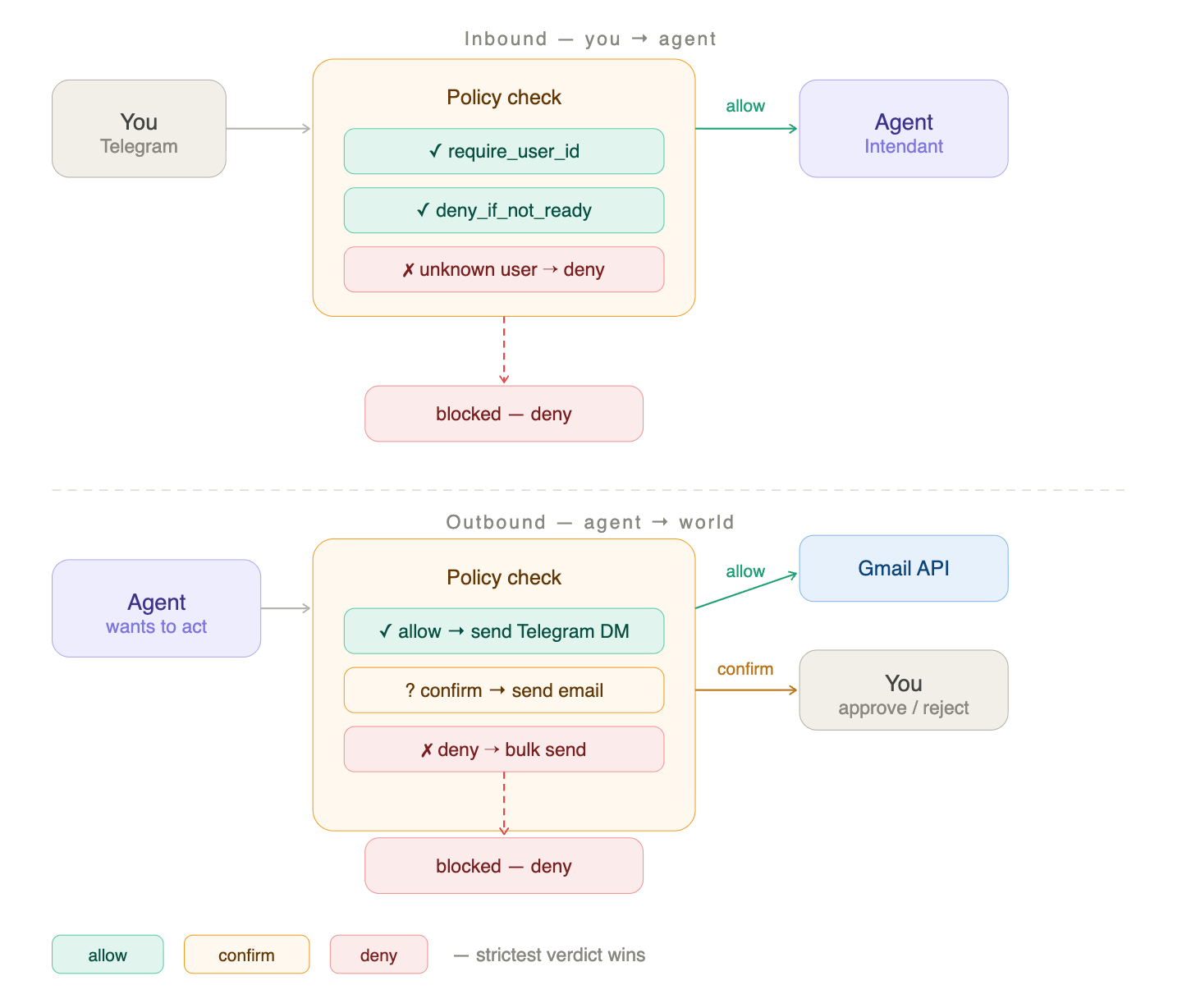
The engine itself is about twenty lines. It doesn’t know what any policy does — it just asks each one for a verdict and picks the strictest. That’s it.
The complexity lives in the policies themselves, and they’re deliberately small. The one that checks your identity is three lines. The one that requires confirmation on a specific channel is three lines. They’re independent, composable, and testable in isolation.
This is the same pattern as the middleware: keep the orchestration dumb, keep the rules simple, compose them to get complex behaviour. A policy that denies destructive actions — deleting emails, removing contacts — is five lines. A policy that requires confirmation outside operating hours is five lines. Stack them with the identity check and you have a surprisingly sophisticated safety layer without a single complex class.
The alternative — one big policy class with conditionals for every case — sounds reasonable until you have fifteen cases and they start interacting with each other. Then it becomes untestable and you stop trusting it. Small composable policies you can test in isolation are policies you’ll actually rely on.
The ones I expect to need break into natural tiers. Identity first: only I can talk to the agent. Then confirmation gates: outbound emails, calendar writes, messages to people not in my contacts — anything where the cost of a mistake is high enough to warrant a tap. Then hard limits: the system should never autonomously delete anything, never bulk-send, never act on spam. Then rate limiting and time-based rules: no more than ten emails a day, confirmation required between midnight and 7am. Each one is a single function that returns a single verdict. You register the ones you want, forget about the ones you don’t, and add new ones without touching existing code.
The ones you want from day one: identity, confirm before sending email, deny destructive actions. Everything else comes later as you discover edge cases in real use.
For a system that acts in your name, that trust is the whole point.
What’s next
The event store and queue — the persistence layer that sits beneath everything before any messages start flowing. Then memory. Then the first interface adapter.
The project is called Intendant — the historical French term for the person who ran the operational layer of an estate so the owner could focus elsewhere.
I’ll write here as I build.
- Louis
Really enjoyed this one!
The envelope pattern is spot on, normalizing the entry point before any business logic touches it feels obvious in hindsight, but almost nobody lays that foundation from day one. And it's far from over-engineered: it's exactly what lets you add WhatsApp or a CLI tomorrow without rewiring everything.
The other thing I like a lot is treating the policy engine as a first-class component from the start. For a system that acts in your name, making trust an architectural responsibility rather than scattered if/else checks after the fact changes everything. Looking forward to the next one!