#19 The world behind the email
The agent knew what every message said. It did not know who Marc was.

For months, Intendant has been reading my emails, triaging them, and acting on them. It knows what every message says. It does not know who sent it.
Marc emails me about a partnership. The agent reads it, classifies it, decides whether to escalate. It does not know Marc is the CTO at a company we already talked to last quarter, that he was introduced by someone I trust, that the last action we agreed on six weeks ago is still open. None of that is in the email. It is in the world behind the email.
The agent was operating without a world model. Every interaction was stateless with respect to the people and things it was acting on.
What a world model is
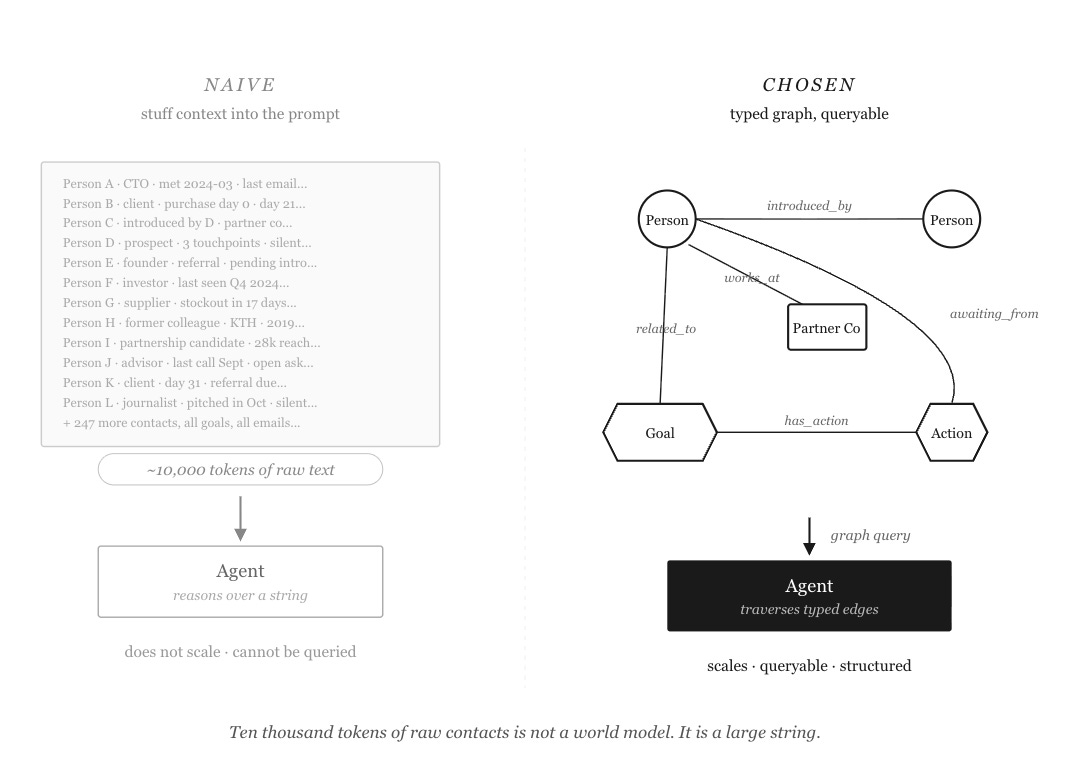
A knowledge graph. The nodes are the things that matter — people, companies, goals, actions, opportunities, cases. The edges are the typed relationships between them.
Not a flat database. The queries that matter are graph queries: what commitments are pending with this person, which goals does this opportunity serve, who introduced me to this contact. Those are natural traversals in a graph. They are awkward joins in a flat table.
The graph is populated by episodes. A goal created, an email processed, a signal advanced or closed. Each episode is a short prose description of what happened. Graphiti reads it, extracts entities and relationships constrained by a typed ontology, and adds them to the graph. Over time, the graph accumulates a picture of how things are connected.
The obvious first move was to skip all of this and stuff more context into the system prompt — a long contacts list and a goal summary before every interaction. It fails for three reasons. It does not scale. It cannot be queried. And it forces the model to reason over raw text rather than structured relationships. Ten thousand tokens of raw contacts is not a world model. It is a large string.
A wall of text the model has to re-read every turn, versus a graph it can traverse.
The ontology
Nine node types: Person, Company, Goal, Action, Period, Content, Place, Opportunity, Case.
Twenty-one edge types. The important one is related_to — the catch-all. The rule I settled on: related_to beats a wrong specific edge. It is better to assert that two things are connected than to assert the wrong kind of connection. Wrong specificity is a silent corruption. Generic is recoverable.
A type map constrains which pairs are allowed. Person → Company gets works_at. Action → Person gets awaiting_from. Unconstrained pairs fall back to related_to. The map is compiled once at import time. The LLM never consults it at runtime — it is a prompt instruction, not a schema enforcement. That gap matters and I’ll come back to it.
The design principle behind extraction: extract nodes aggressively, create edges conservatively. Stubs are cheap. Wrong merges are expensive.
Nine types is not obviously right. But it is the minimum set that covers the things I actually care about. If it turns out to be wrong, the wrapper makes it cheap to change.
Why a real graph database
The honest case for the stack is not that it is simple. It is that it is correct.
FalkorDB is a proper property graph database. When the graph grows — hundreds of people, thousands of edges, queries spanning multiple relationship types — FalkorDB handles it. An SQLite adjacency table does not.
Graphiti adds the temporal layer. You do not just store facts. You store when they were true. If Marc leaves his company, the graph knows what I knew before and after. That kind of temporal reasoning is not something you bolt on later.
The cost is real. Three dependencies for a single-user system with a few dozen contacts today: FalkorDB in Docker, Ollama for local embeddings, Claude for extraction. That is infrastructure before the problem is large enough to prove the choice right.
The deliberate bet: I reached for the right tool before the data justifies it. That is a different kind of mistake than reaching for the wrong tool when the data does justify it. I would rather over-engineer the foundation than under-engineer it and hit the wall later.
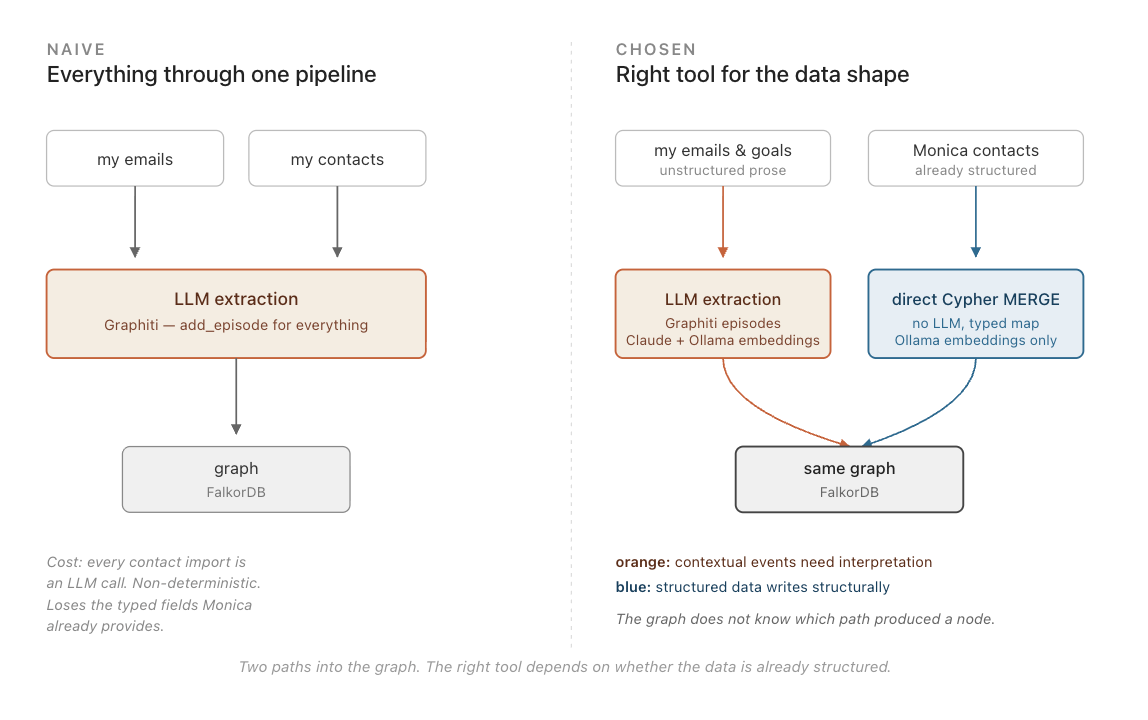
Two paths into the graph
Graphiti’s add_episode is designed for unstructured text. Give it a prose description of what happened and it extracts entities and relationships. That is the right tool for emails, goals, and signal events — contextual, unstructured, needs LLM interpretation.
My contacts database is already structured. Running it through the LLM extraction pipeline would be expensive, imprecise, and unnecessary. The data is already there. The fields are already typed. The relationships already have names.
So the Monica sync takes a different path: zero LLM calls, direct Cypher MERGE, Ollama embeddings only. Each contact becomes a Person node. Each relationship becomes a typed edge. A sync_state watermark tracks when it last ran. The scheduler runs it nightly. The two paths write to the same graph and the graph does not know or care which path produced a given node.
This is the principle I kept coming back to during the build: use the right tool for the data shape. LLM extraction for unstructured events. Structured Cypher writes for structured contacts. Using Graphiti to import a Monica contact list would be like running a PDF through OCR when you already have the source document.
Two write paths into the same graph: LLM extraction for unstructured events, direct Cypher for structured contacts.
The Monica sync is also how the social layer gets typed. Monica stores relationships as strings: “godfather”, “foster parent”, “stepbrother”, “mentor”, “former colleague”. The graph wants typed edges: parent_of, extended_family_of, sibling_of, knows. The translation map is sixty-plus entries. Writing it is the work of understanding the ontology deeply enough to know that “godparent” is parent_of, “best friend” is friend_of, and “former colleague” is knows with a context field — not a generic fallback. The map is not interesting code. The judgment behind it is.
The episode path writes contextual events: what happened, when, what it connected to. The Monica sync writes the social graph: who exists, what their role is, how they relate. The two paths together build something neither builds alone.
The gap automation can’t close
A graph populated only by automated episodes and nightly syncs is still incomplete. The people who matter most are the ones I talk to in person — on calls, at dinners, through introductions. Those conversations do not show up in the email feed, and Monica does not know about the last dinner, the new role, the person I met through someone else.
The enrichment tool closes that gap. After a meeting, I open a web interface, find a contact in the dropdown, and speak a short voice note. The browser captures it, sends the transcript to a FastAPI endpoint, and Claude extracts structured fields: a note, a last-seen date and context, how we met, work information, any relationships mentioned. Those fields get written back to Monica. A SQLite progress tracker marks which contacts have been enriched.
The voice path was the right call. Typing into a CRM after a meeting is friction I will not sustain. Speaking is faster, and the transcript is clean enough for Claude to extract structure from.
What I ruled out
A flat contacts table in SQLite. This handles identity resolution but not graph queries. “Who introduced me to this person” requires traversing a knows edge through an intermediate Person node. Natural graph query, awkward SQL join.
Running Monica contacts through Graphiti’s episode pipeline. Correct structure cannot be made more correct by feeding it through an LLM. It adds cost, introduces non-determinism, and loses the field-level precision that Monica already provides. The right path for structured data is a structured write.
A more complex enrichment flow. The first design had server-side audio transcription, async job queuing, and a review step before writing to Monica. None of that survived contact with reality. The simplest thing that works: speak, extract, write. Three steps, no queue, no review gate. The LLM extracts conservatively enough that a review step added friction without adding safety.
What the first iteration revealed
I expected the world model to be useful eventually, once it had enough data. I did not expect it to start surfacing patterns after thirty emails.
The graph started showing things that were invisible in the flat event log: which people cluster around the same topics, which goals have the most pending actions, which relationships are active and which have gone quiet. None of those patterns were in the individual emails. They emerged from the connections between them.
The patterns were also funny. A graph of your professional relationships is a more honest picture of how you actually spend your attention than anything you would write down deliberately. It is harder to tell yourself a flattering story about your priorities when the graph shows you how the edges actually distribute.
Two things broke during the build. The audio path was the bigger one. The original design sent the recording to a server-side transcription endpoint that fed Claude. I built it, tested it, and found that Claude does not handle audio input the way I assumed — the document content block does not accept audio files. I rewrote the path to use the browser’s built-in speech recognition. Live interim results show while recording, the final text goes directly to the extraction endpoint. Cleaner than what I planned.
The smaller one is the constraint gap. The type map is a prompt instruction, not a schema enforcement. The LLM mostly respects it. Sometimes it doesn’t. A wrong edge gets written and the graph quietly drifts. The dedup utilities I wrote during the build exist for this. They are not yet automated.
Known limitations
The graph is structurally sound but sparsely populated. The ontology is rich. The data is thin. Event-driven episodes and a nightly Monica sync write continuously. Everything else — call transcripts, LinkedIn connections, Pipedrive deals — is backfill scripts that run manually, once. The world model will only be as complete as the data sources wired into it.
LLM extraction is non-deterministic. The entity and edge type maps guide the model but do not enforce schema. A wrong merge — two Person nodes that should be separate, an edge asserted on weak evidence — is a silent corruption. Dedup and merge utilities exist. They are not yet automated.
The enrichment tool is manual. There is no trigger that fires it. The gap between the contacts Monica knows about and the contacts the graph knows about closes only when I open the tool and speak. That is a deliberate constraint for now — I want enrichment to be intentional, not a bulk import that floods the graph with stale data.
The morning briefing surfaces only commitments and relationships. The full ontology can answer richer questions — which goals have the most pending actions, which opportunities are linked to which people, what is overdue. That surface is not yet exposed.
The agent used to know events. Now it knows the beginning of the world behind them.
The world model is not finished. The ontology is right, the data is growing, and the two paths into the graph — events and contacts — are both running. But a graph that tells you something interesting about your relationships is not the graph you build in two weeks. It is the graph you accumulate over time, one episode at a time.
Thirty emails in, it is already telling me things I did not know I had written down. That is faster than I expected.
I’ll keep building.
- Louis
Great write‑up, super clear, and you can feel the “I built this because the simpler version wasn’t actually enough” energy in it.